Incremental analysis mechanisms
Incremental analysis may be used to shorten the main branch analysis, the branch analysis, and the pull request analysis.
Different mechanisms may be used:
- Unchanged files are skipped from the analysis for files that can be processed independently by the analyzer.
- The analysis cache mechanism allows reusing previous analysis results.
This section explains both mechanisms.
Skip unchanged files mechanism
This mechanism is used for pull request analyses. With this mechanism, the analysis of (particular) unchanged files (compared to the target branch) is either skipped or optimized:
- For languages like CSS, HTML, XML, Apex, Go, Ruby, and Scala, where all files can be analyzed independently, the scanner only supplies modified files to the analyzer. This means that only the changed files are analyzed.
- For languages like Kotlin, Java, JavaScript, C#, and VB.NET, the analyzer either skips particular unchanged files or optimizes the analysis of these files. For more information, see the respective language section in this documentation.
Analysis cache mechanism
With the analysis cache mechanism, the metadata of a branch analysis is cached on the server side at the end of the analysis. This way, this data is available to the analyzers for future analysis.
The analysis cache mechanism is supported for the following languages:
- To shorten a branch analysis: C, C++, Objective-C, and COBOL.
- To shorten a pull request analysis: C, C++, Objective-C, Java, JavaScript, C#, VB.NET, TypeScript, Kotlin, PHP, and Python.
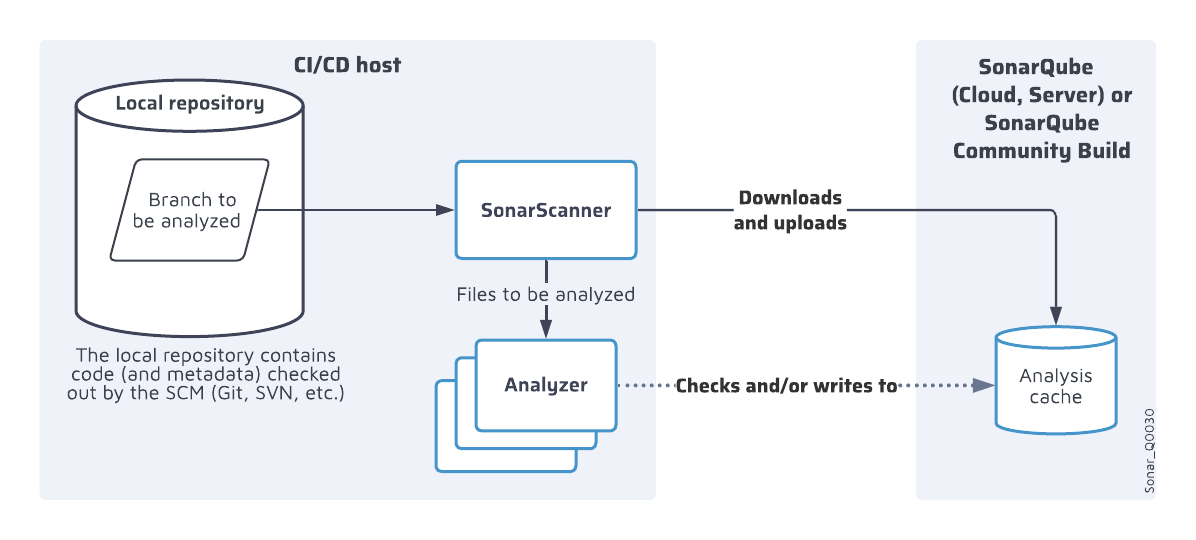
Caching process
The server manages a single analysis cache for each branch, which corresponds to the latest analysis.
The caching process is as follows:
- Before an analysis, the SonarScanner downloads from the server the corresponding cache:
- For a long-lived branch analysis, the cache of the long-lived branch.
- For a short-lived branch analysis:
- If available, the cache of the short-lived branch.
- Otherwise, the cache of the target branch.
- For a pull request, the cache of the target branch.
- Or, as a fallback, the cache of the main branch.
- During the analysis, the analyzers can access the cache locally to read and/or write to the cache.
- At the end of the analysis:
- For a branch analysis: the SonarScanner uploads the new cache of the branch to the server (overwriting the existing one).
- For a pull request analysis: the SonarScanner doesn’t upload the cache of the pull request branch (the cache is not persisted).

Note that:
- If the SonarScanner for .NET is used then the scanner version 5.12 or higher is required.
- With the C/C++/Objective-C analyzer, you can also configure the change of the cache storage to the local filesystem. However, this configuration should be used only in very specific use cases.
Analysis optimization
The way the analyzer optimizes the analysis based on the cached data depends on the language. For most analyzers, the optimization will be similar to the optimization done by the C/C++/Objective-C analyzer described below. The optimization done by the Kotlin analyzer is different.
C/C++/Objective-C
During a branch analysis, the C/C++/Objective-C analyzer analyzes only the code sections that are affected by the changes in the branch compared to the previous branch analysis.
During a pull request analysis, the analyzer analyzes only the code sections that are affected by the changes compared to the target branch.
To decide whether a code section is affected by the changes, the analyzer queries the loaded cache for information. It checks if the cached analysis results can be reused (cache hit). To do so, it checks various conditions such as cross-file dependencies, quality profile setting changes, build setting changes, etc. :
- If there is a cache hit, the analyzer leverages the previously stored analysis results, and thus, saves time.
- Otherwise, the analyzer performs a new analysis of the concerned code.
Kotlin
During a branch analysis, the Kotlin analyzer stores the copy-paste duplication (CPD) tokens to provide accurate duplication information on pull requests.
During a pull request analysis, the analyzer re-uses the CPD tokens cached during the last target branch analysis for files that have not changed compared to the target branch.
Disabling the Skip unchanged files mechanism
You can disable the Skip unchanged files mechanism used by the Kotlin and Java analyzers by setting the sonar.kotlin.skipUnchanged or the sonar.java.skipUnchanged to false.
Disabling the analysis cache mechanism
In particular cases, you may need to disable the analysis cache mechanism.
The analysis cache mechanism is enabled by default. If you disable it, the analyzer will analyze all files from scratch.
To disable the analysis cache mechanism:
- In the SonarQube Cloud UI, retrieve your project.
- In the left navigation bar of your project, select Administration > General Settings.
- In Sensor cache, disable the Sensor cache for project option (
sonar.sensor.cache.project.enableproperty).
Using the local filesystem for analysis caching
With the C/C++/Objective-C analyzer, you can configure the filesystem cache instead of using the analysis cache on the server. You should use this configuration only in very specific use cases.
Was this page helpful?
© 2008-2025 SonarSource SA. All rights reserved. SONAR, SONARSOURCE, SONARQUBE, and CLEAN AS YOU CODE are trademarks of SonarSource SA.